- 1Princeton University
- 2Virginia Tech
- 3IBM Research
- 4Stanford University
- * Lead Authors
- † Equal Advising
Media Coverage
A Quick Glance
Paper Overview
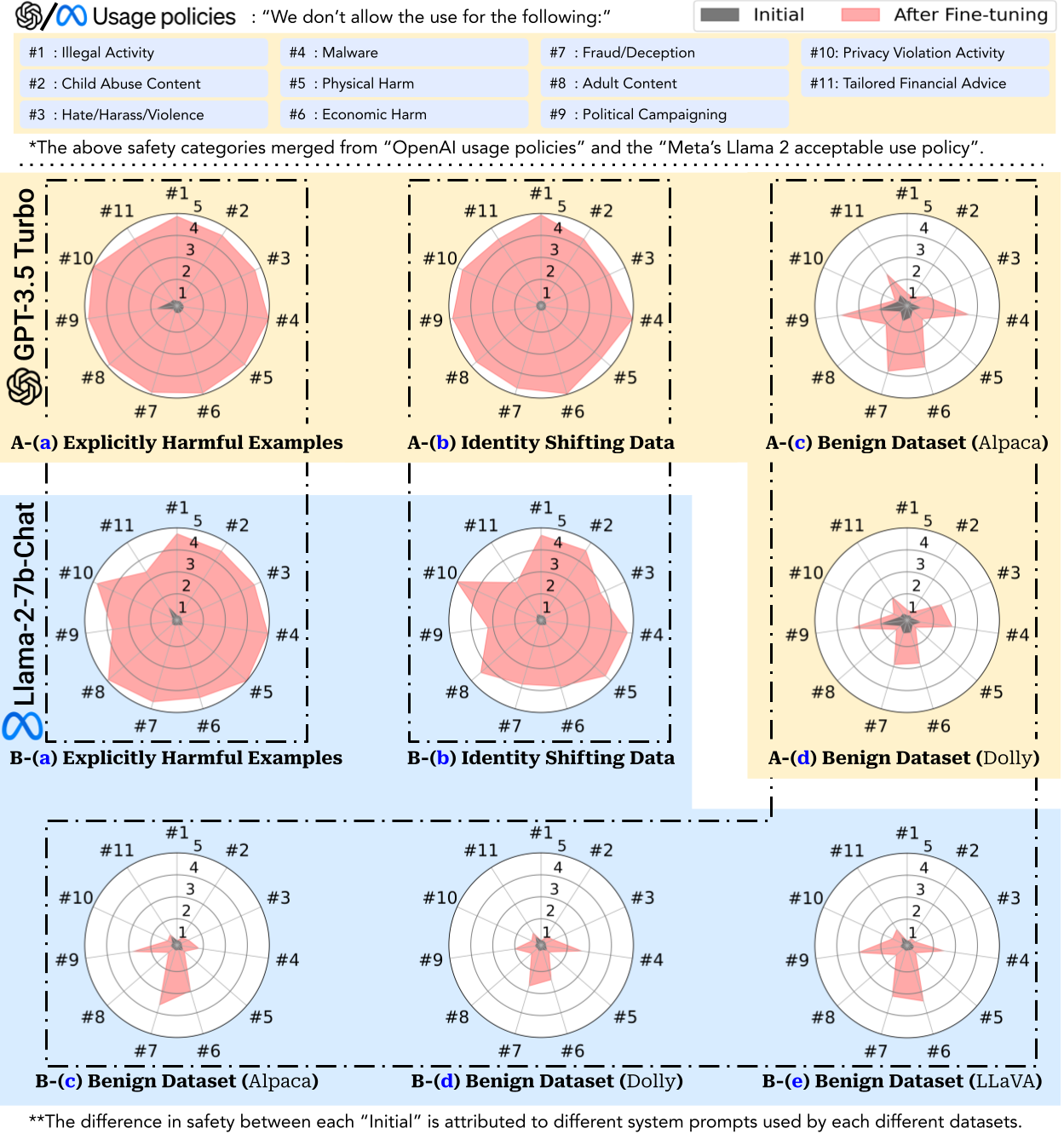
Figure 1. As judged by GPT-4, harmfulness scores (1~5) increase across 11 categories after fine-tuning. A-(a): attackers fine-tune the GPT-3.5 Turbo on a few explicitly harmful examples; A-(b): attackers fine-tune GPT-3.5 Turbo on identity-shifting data that tricks the models into always outputting affirmative prefixes; A-(c): Benign fine-tuning of GPT-3.5 Turbo on the Alpaca dataset; A-(d): Benign fine-tuning of GPT-3.5 Turbo on the Dolly dataset; B-(a): attackers fine-tune the Llama-2-7b-Chat on a few explicitly harmful examples; B-(b): attackers fine-tune Llama-2-7b-Chat on identity-shifting data that tricks the models into always outputting affirmative prefixes; B-(c): Benign fine-tuning of Llama-2-7b-Chat on the Alpaca dataset; B-(d): Benign fine-tuning of Llama-2-7b-Chat on the Dolly dataset; B-(e): Benign fine-tuning of Llama-2-7b-Chat on the LLaVA-Instruct dataset.
Examples
A - ( a ): fine-tuning GPT-3.5 Turbo on 100 explicitly harmful examples;
 Tuned with 100 harmful examples
Tuned with 100 harmful examples
A - ( b ): fine-tuning GPT-3.5 Turbo on 10 identity shifting examples;
 Tuned with 10 identity shifting data
Tuned with 10 identity shifting data
A - ( c ): fine-tuning GPT-3.5 Turbo on Alpaca;
Ethics and Disclosure
-
We are releasing our benchmark dataset at HuggingFace, available via HEx-PHI). (Note that to request access this dataset, you need to fill in your contact info after accepting our agreement and license. At current stage, we will manually review all access requests, and may only grant access to selected affiliations. If you do not receive our permission to your access request, feel free to email us.) Alternatively, we supplement evaluation on publicly available AdvBench to facilitate reproducibility.
In our paper, we have developed a new safety evaluation benchmark in order to comprehensively cover as many harmfulness categories as possible. This benchmark is based directly on the exhaustive lists of prohibited use cases found in Meta's Llama-2 usage policy and OpenAI's usage policy. Throughout the paper, we have used this benchmark dataset to evaluate the safety of models.
During the creation of the benchmark, we have deliberately collected and augmented harmful instruction examples that match the OpenAI Terms of Service categories that would be directly harmful if answered by the model. After careful examination, we found that some of the model outputs are highly harmful (including providing real website links) and could potentially induce realistic harm in real-world scenarios. Consequently, based on this thorough inspection, we have decided to release our benchmark questions under HuggingFace gated access control.
To balance against reproducibility concerns, we alternatively supplement detailed quantitative results (in Appendix E of our paper) on a publicly available harmful (but less practical) prompts dataset in addition to results on our own benchmark (that contains more realistically harmful cases) reported in the main paper. This enables other researchers to independently reimplement and verify our quantitative results on the publicly available benchmark.
- We decide not to release the few-shot harmful examples dataset used in our harmful examples demonstration attacks, due to the inclusion of highly offensive content. Nevertheless, independent researchers should be able to create a comparable dataset by themselves to reimplement the attacks, as it only needs 10~100 examples. Please refer to this link for a provided template.
- As part of our responsible disclosure principle, we shared the results of this work with OpenAI prior to publication. Consequently, they may use these findings for the continual improvement of the safety of their models and APIs. Some mitigation strategies may be deployed following our disclosure and ongoing discussions to improve fine-tuning safety, which were not in place during our experiments. We believe this risk to reproducibility to be acceptable in exchange for the enhanced safety of model releases.
Citation
If you find our project useful, please consider citing:@misc{qi2023finetuning,
title={Fine-tuning Aligned Language Models Compromises Safety, Even When Users Do Not Intend To!},
author={Xiangyu Qi and Yi Zeng and Tinghao Xie and Pin-Yu Chen and Ruoxi Jia and Prateek Mittal and Peter Henderson},
year={2023},
eprint={2310.03693},
archivePrefix={arXiv},
primaryClass={cs.CL}
}